本文介绍如何搭建3D目标检测框架,使用docker快速搭建MMDetection3D的开发环境,实现视觉3D目标检测、点云3D目标检测、多模态3D目标检测等等。
需要大家提前安装好docker,并且docker版本>= 19.03。
文章来源地址https://www.uudwc.com/A/12gmG/
1、下载MMDetection3D源码
https://github.com/open-mmlab/mmdetection3d

git clone https://github.com/open-mmlab/mmdetection3d.git
主要特性
-
支持多模态/单模态的检测器
支持多模态/单模态检测器,包括 MVXNet,VoteNet,PointPillars 等。
-
支持户内/户外的数据集
支持室内/室外的 3D 检测数据集,包括 ScanNet,SUNRGB-D,Waymo,nuScenes,Lyft,KITTI。对于 nuScenes 数据集,我们也支持 nuImages 数据集。
-
与 2D 检测器的自然整合
MMDetection 支持的 300+ 个模型,40+ 的论文算法,和相关模块都可以在此代码库中训练或使用。
模块组件
| 主干网络 | 检测头 | 特性 |
|
|
|
算法模型
| 激光雷达 3D 目标检测 | 相机 3D 目标检测 | 多模态 3D 目标检测 | 3D 语义分割 |
|
|
|
|
2、获取MMDetection3D镜像
我们先看看mmdetection3d-main/docker/Dockerfile文件,用来构建docker镜像的
ARG PYTORCH="1.9.0"
ARG CUDA="11.1"
ARG CUDNN="8"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0 7.5 8.0 8.6+PTX" \
TORCH_NVCC_FLAGS="-Xfatbin -compress-all" \
CMAKE_PREFIX_PATH="$(dirname $(which conda))/../" \
FORCE_CUDA="1"
# Avoid Public GPG key error
# https://github.com/NVIDIA/nvidia-docker/issues/1631
RUN rm /etc/apt/sources.list.d/cuda.list \
&& rm /etc/apt/sources.list.d/nvidia-ml.list \
&& apt-key del 7fa2af80 \
&& apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub \
&& apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
# (Optional, use Mirror to speed up downloads)
# RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
# pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Install the required packages
RUN apt-get update \
&& apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Install MMEngine, MMCV and MMDetection
RUN pip install openmim && \
mim install "mmengine" "mmcv>=2.0.0rc4" "mmdet>=3.0.0"
# Install MMDetection3D
RUN conda clean --all \
&& git clone https://github.com/open-mmlab/mmdetection3d.git -b dev-1.x /mmdetection3d \
&& cd /mmdetection3d \
&& pip install --no-cache-dir -e .
WORKDIR /mmdetection3d
这里有ARG PYTORCH="1.9.0"、ARG CUDA="11.1"、ARG CUDNN="8"这些关键参数,可以根据需求修改
然后执行命令:docker build -t mmdetection3d docker/
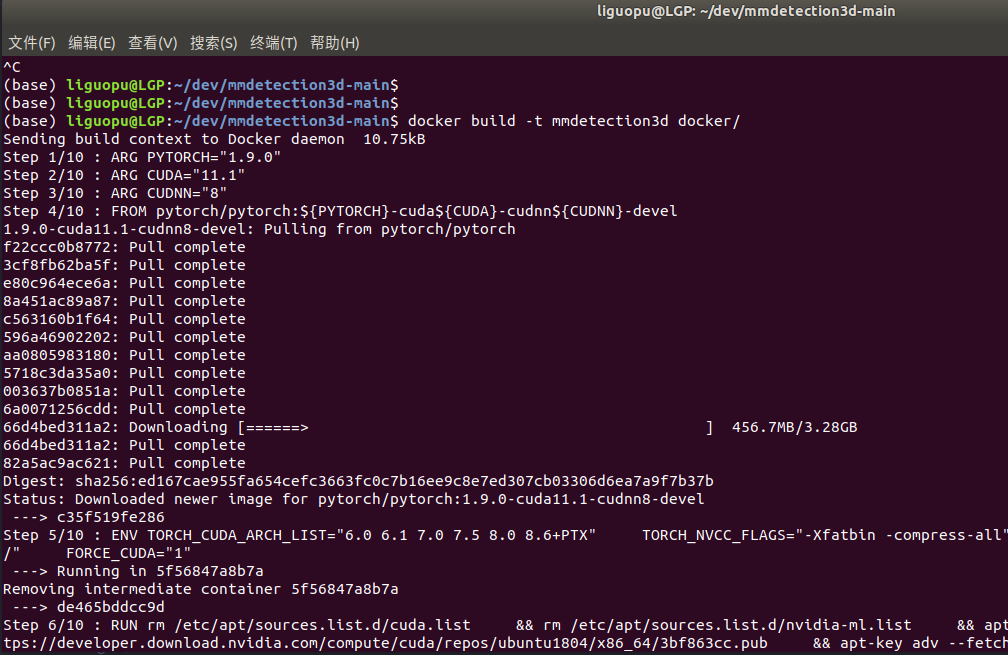
拉取docker镜像会比较慢,如果大家也是这个版本的,可以放到网盘,分享给大家
等待构建完成:
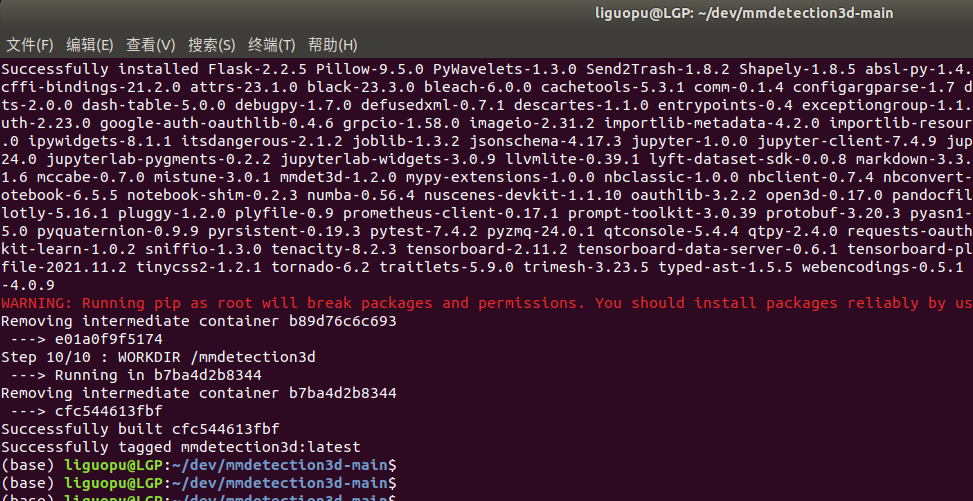
用命令docker images查看镜像信息,能看到mmdetection3d镜像:

3、使用MMDetection3D镜像
打开镜像:方式一(常规模式--支持使用GPU)
docker run --gpus all -it mmdetection3d:latest /bin/bash
打开镜像:方式二(增强模式--支持使用GPU、映射目录、设置内存)
docker run -i -t -v /home/liguopu/:/guopu:rw --gpus all --shm-size 16G mmdetection3d:latest /bin/bash平常进入了docker环境,然后创建或产生的文件,在退出docker环境后会“自动销毁”;或者想运行本地主机的某个程序,发现在docker环境中找不到。
我们可以通过映射目录的方式,把本地主机的某个目录,映射到docker环境中,这样产生的文件会保留在本地主机中。
通过-v 把本地主机目录 /home/liguopu/ 映射到docker环境中的/guopu 目录;其权限是rw,即能读能写。
默认分配很小的内参,在训练模型时不够用,可以通过参数设置:比如,我电脑有32G内参,想放16G到docker中使用,设置为 --shm-size 16G。
4、测试MMDetection3D开放环境
验证安装是否成功,在终端先输入python,然后输入以下代码打印版本号
import mmdet3d
print(mmdet3d.__version__)效果如下:

测试一下模型推理
我们需要下载配置文件和模型权重文件。
mim download mmdet3d --config pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car --dest .下载将需要几秒钟或更长时间,这取决于的网络环境。
完成后会在当前文件夹中发现两个文件
-
pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth
写一个代码如下:
from mmdet3d.apis import init_model, inference_detector
config_file = 'pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py'
checkpoint_file = 'hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth'
model = init_model(config_file, checkpoint_file)
output = inference_detector(model, 'demo/data/kitti/000008.bin')
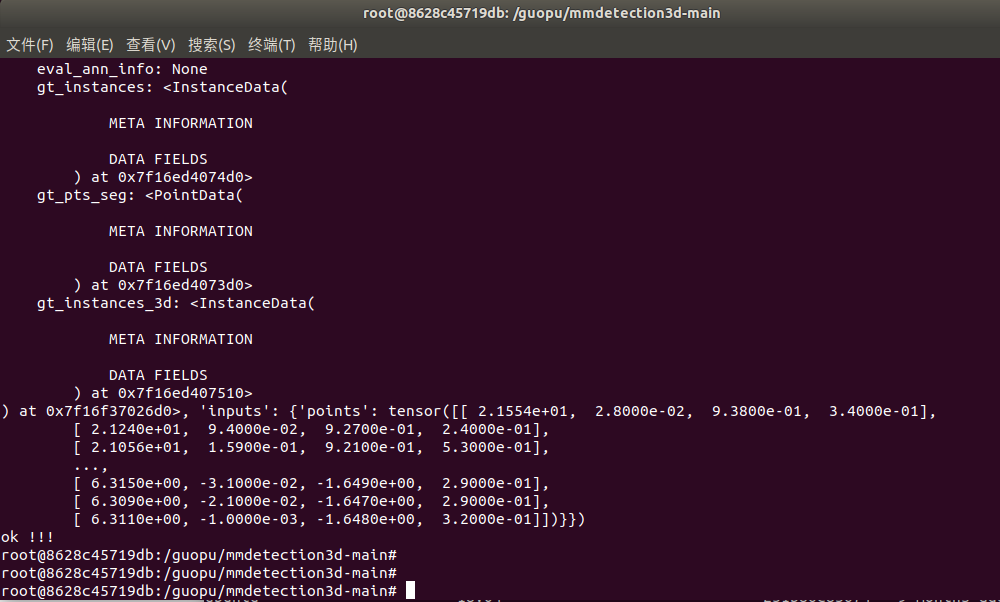
print("inference_detector output:", output)
print("ok !!!")
能看到模型成功推理,并输出结果信息:
分享完成啦~文章来源:https://www.uudwc.com/A/12gmG/